python图片识别文字
作者:YXN-python 阅读量:348 发布日期:2024-11-05
图片识别文字
方法一:easyocr
easyocr识别图片文字
官网地址:https://www.jaided.ai/easyocr/modelhub/
pip install easyocr
def ocr_text(img_path):
import easyocr
texts = []
reader = easyocr.Reader(['ch_sim', 'en']) # 指定语言
result = reader.readtext(img_path) # 读取图片中的文字
for detection in result:
texts.append(detection[1]) # 打印识别的文字
return texts方法二:ddddocr
ddddocr识别图片文字
pip install ddddocr
def dor_text(img_path):
import ddddocr
ocr = ddddocr.DdddOcr(show_ad=False)
return ocr.classification(open(img_path, 'rb').read())方法三:Tesseract-OCR
安装
第一步:安装必要的库
pip install pillow
pip install pytesseract
第二步:手动安装Tesseract-OCR
先从如下网址上下载安装包,然后直接安装(需要记住安装路径哦)。
网址:https://digi.bib.uni-mannheim.de/tesseract/?C=M;O=D
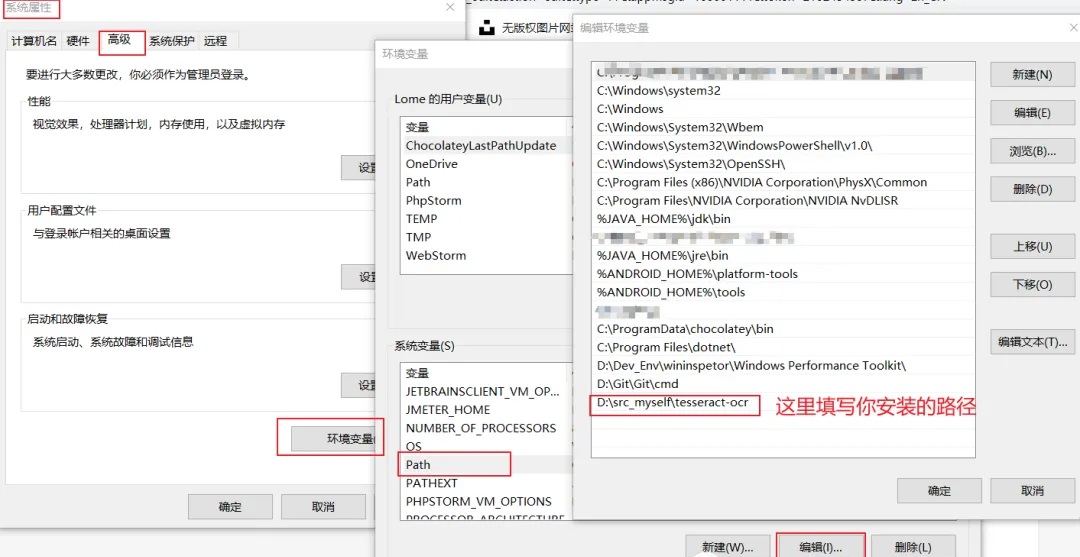
安装后,将安装目录添加到系统环境变量中。
图片文字提取
import pytesseract
from PIL import Image
# 如果没有将tesseract的安装目录添加到系统环境变量中,则需要指定安装路径,
# pytesseract.pytesseract.tesseract_cmd=r"D:\src_myself\tesseract-ocr\tesseract.exe"
# 先使用pillow库打开图片
img = Image.open('test_007.png')
# 调用pytesseract库提取文字,请注意指定语言lang='chi_sim'哦,否则中文无法识别出来
text = pytesseract.image_to_string(img, lang='chi_sim')
print(text)方法四:PaddleOCR
1、PaddleOCR介绍
PaddleOCR是一个可以识别图片中文字的工具,可以将图片中的文字转换成电脑可以认识的文字。简单来说,它的原理是使用深度学习技术,通过训练模型来识别图片中的文字。具体来说,它会通过一系列处理,比如缩放、灰度化、去噪等操作,来提高文字识别的准确率。然后,它会使用深度学习模型来检测图片中的文字区域,并将其转换成电脑可以识别的边界框。最后,它会使用另一个深度学习模型来识别边界框中的文字,并将其转换成电脑可以识别的文字。这样,就可以实现将图片中的文字转换成电脑可以识别的文字的功能了。
2、PaddleOCR功能特点
- 支持多种OCR任务:PaddleOCR支持多种OCR任务,包括文字检测、文字方向检测、多语种OCR、手写体OCR等,可以满足不同场景下的OCR需求。
- 识别精度高:PaddleOCR的深度学习模型经过大量的训练和优化,可以在各种复杂场景下实现高精度的OCR识别,具有较高的识别准确率。可准确识别不同字体、字号、字形的文字图像,实现超越人眼识别率的准确率。
- 易于使用:PaddleOCR提供了丰富的预训练模型和模型优化技术,可以快速部署和使用OCR功能,同时也提供了简单易用的API接口和开发文档,方便用户进行二次开发和定制化。
- 开源免费:PaddleOCR是一个开源免费的OCR工具,用户可以免费获取源代码和训练数据,自由使用和修改,方便用户进行二次开发和定制化。
总之,PaddleOCR是一个高效、精准、易用、开源免费的OCR工具,可以为用户提供全面的OCR解决方案,满足不同场景下的OCR需求。
3、安装
pip install paddlepaddle
pip install paddleocr
4、PaddleOCR使用方法
PaddleOCR的使用方法可以分为文本检测和文本识别两个步骤。
示例一:
使用PaddleOCR进行文字检测和识别:
from paddleocr import PaddleOCR, draw_ocr
ocr = PaddleOCR()
# 读取图片
img_path = 'example.jpg'
result = ocr.ocr(img_path, cls=True)
# 可视化识别结果
image = draw_ocr(img_path, result, font_path='simfang.ttf')
image.show()示例二:
以下是一个PaddleOCR多任务识别示例,展示如何同时进行文字检测、文本方向检测和文字识别:
from paddleocr import PaddleOCR, draw_ocr
from PIL import Image
# 初始化PaddleOCR模型
ocr = PaddleOCR(use_angle_cls=True, lang='ch', use_gpu=False, det=True, rec=True, cls=True)
# 读取图片
img_path = 'multi_task_example.jpg'
image = Image.open(img_path)
# 进行文字检测、文本方向检测和文字识别
result = ocr.ocr(img_path, cls=True)
# 可视化识别结果
image = draw_ocr(image, result, font_path='simfang.ttf')
image.show()示例三:
以下是一个更为复杂的PaddleOCR定制化识别示例,展示如何使用PaddleOCR进行多语种文字识别和手写体文字识别:
from paddleocr import PaddleOCR, draw_ocr
from PIL import Image
# 初始化PaddleOCR模型
ocr = PaddleOCR(use_angle_cls=True, lang='en', use_gpu=False)
# 读取图片
img_path = 'complex_example.jpg'
image = Image.open(img_path)
# 进行多语种文字识别
result = ocr.ocr(img_path, cls=True)
# 可视化识别结果
image = draw_ocr(image, result, font_path='simfang.ttf')
image.show()
# 进行手写体文字识别
handwriting_ocr = PaddleOCR(use_angle_cls=True, use_gpu=False, det_model_dir='handwriting_det', rec_model_dir='handwriting_rec')
result_handwriting = handwriting_ocr.ocr('handwriting_example.jpg', cls=True)
image_handwriting = Image.open('handwriting_example.jpg')
image_handwriting = draw_ocr(image_handwriting, result_handwriting, font_path='simfang.ttf')
image_handwriting.show()5、PaddleOCR应用场景
PaddleOCR 在许多不同的应用场景中都能发挥作用,包括但不限于:
- 文字识别:PaddleOCR 可用于识别图像中的各种语言的文字,包括印刷体和手写体文字。
- 文档数字化:将纸质文档、书籍或手写笔记等转换为可编辑的电子文档,便于存档和检索。
- 自然场景文字识别:在照片、视频或实时摄像头图像中识别并提取文字,如车牌识别、街景文字识别等。
- 身份证、驾驶证等证件识别:用于自动识别和提取身份证、驾驶证等证件中的文字信息。
- 商业应用:用于票据识别、表格文字提取、商品标签识别等商业场景。
- 辅助工具:作为辅助工具,帮助视力受损者阅读文本。
- 教育领域:用于批改作业、识别学生答题卡等教育场景。
- 文字翻译:结合机器翻译技术,实现实时的图像翻译。
YXN-python
2024-11-05