Power BI--DAX函数总结(转)
作者:YXN 阅读量:97 发布日期:2021-09-20
1.日期与时间函数:
01. 如何改变日期格式
已有时间栏的情况下如何改变日期格式,比如从January到01月
步骤:1.新建column,使用FORMAT函数创建一个新的月份列
Month3 = FORMAT('表名字'[month2], "MM月")

然后回到数据可视化界面, 将新创建的月份列当作X轴的值。搞定!
1.计算年初至今累计--TOTALYTD函数
例如计算年初至今累计的销售金额:
[年累计金额]:=
TOTALYTD([销售金额],
'日历年'[日期])
# 如果要加上一个时间截止点,则写为:
[年累计截止金额]:=
TOTALYTD([销售金额],
'日历年'[日期],
'日历年'[日期]<DATE(2016,6,1))
# 同理计算季度初至今累计--TOTALQTD, 计算月初至今累计--TOTALMTD
2.计算上一年/季度/月的销售额--DATEADD函数
[上一年销售额]: =
CALCULATE([销售金额],
DATEADD('日历年'[日期],-1,YEAR))
--YEAR可改为QUARTER,MONTH,DAY
--将-1改为+1则时间后移
3.计算同比/环比
# 月同比--今年每月的销售金额相比去年同月份增长的比率
[上一年销售额]: =
CALCULATE([销售金额],
DATEADD('日历年'[日期],-1,YEAR))
[同比]: =
DIVIDE([销售金额]-[上一年销售额],
[上一年销售额])
# 月环比--这月与上月相比销售额增长的比率
[上一月销售额]: =
CALCULATE([销售金额],
DATEADD('日历年'[日期],-1,MONTH))
[环比]: =
DIVIDE([销售金额]-[上一月销售额],
[上一月销售额])
4. 计算两个日期之间间隔--DATEDIFF
[时间间隔]: =
DATEDIFF([开始日期],
[结束日期],
'Y') --参数"Y"换成"M"或"D",则分别对应月和日
--也可以改成HOUR,MINUTE,SECOND计算小时,分,秒
5.其他日期时间函数:
DATE(2009,7,8) --结果返回'2009/7/8 0:00:00'
DATEVALUE("8/1/2009") --将文本形式的日期转换为日期时间格式的日期,结果返回
'2009/8/1 0:00:00'
DATEADD([日期],3,DAY) --日期加减函数
EOMONTH([日期],3) --返回指定月份数之前或之后的月份的最后一天的日期
EDATE([日期],3) --返回在开始日期之前或之后指示的月数的日期
YEAR(),MONTH(),DAY(),HOUR(),MINUTE(),SECOND()
NOW() --返回当前的日期时间 TODAY()--返回当前的日期
WEEKDAY([日期],1) --一周中的第几天,参数1代表从星期日开始计数,参数2代表从星期一开始计数
参数3代表从星期一开始计数,但到星期六结束
WEEKNUM([日期],1) --一年中的第几周,1代表从周日开始计数,2代表从周一开始计数
2. 筛选器函数:
1.ALL, ALLEXCEPT, ALLSELECTED
ALL(table/column) --ALL用来清除整个表或某个字段的筛选条件,通常配合CALCULATE使用
ALLEXCEPT(table/column) --删除表中除已应用于指定列的筛选器之外的所有上下文筛选器
ALLSELECTED(table/column) --从当前查询的列和行中删除上下文筛选器,同时保留所有其他上下文筛选器或显式筛选器
2.CALCULATE(<expression>,<filter1>,<filter2>...)
--Calculate可以应用在多个表
Calculate使用AND关系时可直接在条件间加',',但表达“或”时,必须用'||',而且连接的两个条件
必须引用同一列。
Calculate中当“[列] = 固定值”这种筛选搞不定时,可用filter/all/values筛选器搭配使用
布尔筛选表达式
布尔表达式筛选器是计算结果为 TRUE 或 FALSE 的表达式。 必须遵守下面几项规则:
可以引用单个表中的列。
它们不能引用度量值。
它们不能使用嵌套的 CALCULATE 函数。
3.FILTER(table,<filter>) --返回值:只包含筛选行数据的表
--筛选时对表进行逐行扫描,计算量很大,所以选择筛选的表尽量为lookup表
4.HASONEVALUE(<columnName>) --将 columnName 的上下文筛选为只剩下一个非重复值时,
将返回 TRUE。 否则为 FALSE。
5.RELATED(<column>) --将“一”端的列值添加到“多”端的表中
RELATEDTABLE(<tableName>) --将“多”端关联的表数据添加到“一”端的列上,
返回的是一张表
6.VALUES(<TableNameOrColumnName>) --返回由一列构成的一个表,该表包含来自指定表或列的
非重复值。 换言之,重复值将被删除,仅返回唯一值。
7.EARLIER函数:
例如我们有“产品名称”和“销售金额”两列数据。基于此,我们希望计算出每个产品的销售金额排名。
COUNTROWS(
FILTER('产品销售表',
EARLIER('产品销售表'[销售金额])<'产品销售表'[销售金额])
)+1
--EARLIER=当前行,按照当前行进行逐行扫描,SUMX+FILTER+EARLIER
是Power Pivot中比较常用的函数组合,由于Earlier针对每一行数据都进行计算,
所以理论上计算量相当于数据行数的平方。如果有10行数据,则需要计算100次,
所以数据量大的时候大家使用要小心,有可能会造成模型计算缓慢。
3. 逻辑判断函数:
1.CONTAINS(InternetSales, [ProductKey], 214, [CustomerKey], 11185)
--是否同时存在销售给客户 11185 的产品 214 的任何 Internet 销售额。
2.ISBLANK(column) --判断该列中某个值是否为空
3.ISNONTEXT(column) --检查某个值是否不是文本
4.ISNUMBER(column) --检查某个值是否为数字
5.ISTEXT(column) --检查某个值是否为文本
6.ISLOGICAL(column) --检查某个值是否是逻辑值
4. 逻辑函数:
1.IF(<logical_test>,<value_if_true>, value_if_false)
--检查是否满足作为第一个参数提供的条件。 如果该条件为 TRUE,则返回一个值;
如果该条件为 FALSE,则返回另一个值,用法与excel类似
2.SWITCH(<expression>,条件1,值1,条件2,值2) --根据值列表计算表达式,
并返回多个可能的结果表达式之一。
5.统计函数:
1. SUMX(table,<expression>) --SUMX与CALCULATE功能类似,但SUMX属于迭代函数,计算量大
--同理AVERAGEX,MINX.MAXX用法相同
2. SUM(),MAX(),MIN(),SQRT()
DISTINCTCOUNT()--计算去重后列所包含的元素个数
COUNTROWS() --计算表的行数
COUNT() --计算列中包含数字的单元的数目
COUNTA() --计算列中不为空的单元的数目
COUNTBLANK() --计算列中空白单元的数目
3.DIVIDE(分子,分母) --在DAX中涉及到除法必须用DIVIDE
4.CROSSJOIN(<table1>, <table2>) --生成笛卡尔积表
SUMMARIZE(<table>, <groupBy_columnName>,<name>,<expression>)
--table,任何返回数据表的 DAX 表达式。
groupBy_columnName将使用该列中找到的值创建摘要组,此参数不能是表达式。
name,给予总计或汇总列的名称,包含在双引号内。
expression,任何返回单个标量值的 DAX 表达式,其中,表达式将计算多次(针对每行/上下文)。
GENERATE(<table1>, <table2>)--生成笛卡尔积表6.文本函数:
1. LEFT(),RIGHT(),MID(),FIND(),SEARCH(),LEN() ---字符串提取函数
2. REPLACE(),SUBSTITUTE() --字符串替换函数
3. TRIM(),LOWER(),UPPER()
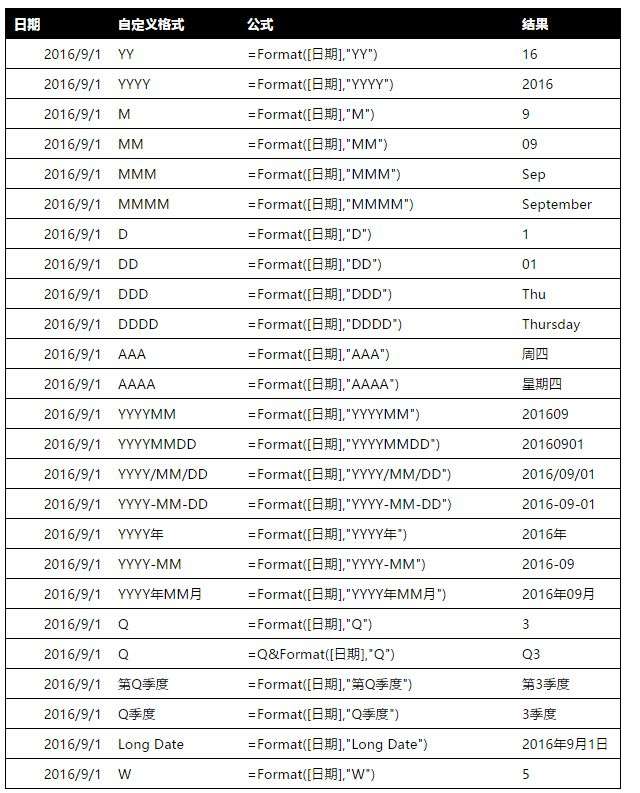
4. FORMAT函数,对于日期格式的自定义设置如下图:
出处:

YXN
2021-09-20